One of the most interesting things I’ve been studying in the past year has been type theory. I feel that type theory is an area where a lot of separate fields can come together in a good design. In strongly typed languages, language implementation efficiency, syntax and language semantics all leave essential marks in the type system, and conversely, flaws in the type system can impair all of them.
Type theory was invented by Bertrand Russell as a solution to his own well-known paradox, which cast doubt on the foundations of mathematics upon its discovery. The problem posed by the paradox is essentially: given a set of all sets that do not contain themselves, does that set contain itself? Another interesting problem arising from self-referentialism. Type theory resolves this issue by classifying the members of sets according to some type, and in such a system a set definition like this one is not permissible.
(The drama surrounding Russell’s paradox and Principia Mathematica can now also be read in the form of a “logicomix” graphic novel by Doxiadis et al!)
Type theory did not end its life as a metamathematical hack that solved a set theoretical problem. It has now come of age. Type systems are, of course, at the heart of the development of many modern programming languages. Java, C#, Lisp, ML and Haskell are but a few of the ones that depend completely on a nontrivial type system. (Even though C and C++ have type systems, they are kept in a crippled state by the fact that the programmer is allowed to ignore their commandments at will.)
What is the benefit of a type system in a programming language? In the words of Benjamin Pierce,
A type system is a syntactic method for automatically checking the absence of certain erroneous behaviors by classifying program phrases according to the kinds of values they compute.
So, generally speaking, a type system helps distinguish correct programs from incorrect programs. The parser also does part of this job, of course, since many programs that cannot compile will not parse. But there are programs that are syntactically correct but at the same time semantically unsound according to the evaluation rules of the language. Consider the following Java statement:
T x = new U(); |
This is clearly syntactically acceptable, but is it semantically valid? In order for it to be, either U needs to be the same type as T, or a subtype of T. But Java programmers are free to define new subtypes of existing types in source code. In order for the parser to check the correctness of the assignment, it seems that either the grammar would become enormously large, or it would place awkward restrictions on Java syntax. So we leave more refined aspects of correctness to the type checker, which is applied later, post-parsing.
What does a type system look like? As used in programming languages today, a type system consists of a set of typing judgments. The judgments can be stacked together to form the typing derivation of an expression in the language. Every expression normally has a unique typing derivation, and when a type can be derived, we call the expression well typed. As Benjamin Pierce’s formulation suggests, each typing rule makes some assumptions about the kinds of values that constitute the various parts of an expression, and then says something about the kind of value that will be computed by the expression as a whole.
Type systems can look prohibitive at first sight, since they use quite a few algebraic symbols. But in general, the structure and interrelationships between the symbols is the most important thing to discern from them, and focussing on this aspect makes reading them much easier.
In the following mini-type system, typing judgments will have the form 
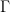


if (a) {b} else {c} |
in a java-like language. The typing context 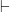
A fragment of a minimal system might look like the following.

Three typing rules have been introduced here, T-ASGN for assignments, T-IF for if-statements, and T-BINOP for binary operations on integers, like + and -.
Every rule has the same structure: above the line, assumptions that must hold true for the rule to be applied; below the line, the conclusion we may draw if the assumptions are true.
Above, the following example was given.
T x = new U(); |
Using T-ASGN, we can type an assignment statement like this one. The assumption T <: U says that T is a subtype of U. We have also assumed a lookup function vartype which gives the declared type of the variable we assign to. In English, we can read the rule T-ASGN as saying: “Assuming that the type of the right hand side is a subtype of, or the same type as, the declared type of the variable, the assignment will evaluate to a value that has the declared type of the variable”. Of course not all programming languages implement assignment in this way.
In the T-BINOP rule, we must of course substitute an actual operation on integers for the special word intBinop for it to be valid. For addition, the rule can be read as “Assuming that the left hand side and the right hand side are both integers, then the result is also an integer”.
Finally, the T-IF rule says “assuming that the truth condition is a boolean, and that the two alternative paths have the same type, then the if-statement evaluates to the same type as that of the two conditional paths”.
The shape of the type system follows the evaluation rules for the language quite closely, so that a well-typed term is also always possible to evaluate. We can thus avoid accepting programs that might get stuck without any valid evaluation rule at some point. (Consider what happens in Python if you try to invoke a method on an object, and the object doesn’t have a method with that name.) We are not limited to tracking just the kinds of values being computed in a type system. We can track various kinds of safety properties, such as memory regions being violated, as well, or we may track multiple properties at once. Type and effect systems is one way of tracking both values being computed and resource violations.
A good source of more information on type systems applied to programming languages would be Benjamin Pierce’s Types and Programming Languages.
Post a Comment